The last week or so I've been exploring the pros and cons of three Speech to Text services. Bing Speech, IBM Watson and AWS Transcribe using a .Net Core 2.0 backend and an Angular 6 client. These are my findings.
Quick Links
- Example code for this post
- Bing Speech
- Bing Speech Documentation
- IBM Watson Speech to Text
- IBM Watson Speech to Text Documentation
- AWS
- AWS S3
- AWS Transcribe
- AWS Transcribe Documentation
- AWS .Net Toolkit
- AWS IAM
Bing Speech Service
The first of three that I implemented was the Bing Speech to Text service since I already have an Azure account. The documentation is pretty clear and the implementation did not take long to set up with Authentication cookies so Microsoft has done a good job there. Here are the following PROS and CONS:
Pros
- Supports the largest range of languages of the three.
- It's fast.
- Easy to implement.
- Three modes: interactive, conversation and dictation.
Cons
- Some modes are limited to 10 seconds of audio within a 15-second clip.
- Modes that can handle more than 10 seconds of audio require a client library to be imported.
Implementation
I've said it's easy to implement, so let me prove it. Firstly grab yourself a subscription key to the free Bing Speech API trial Make note of the subscription key. If you're looking at the provided code, put the subscription key in the appsettings.json file in the BingSubscriptionKey field.
"MyConfig": {
"UseProxy": "false",
"ProxyHost": "...",
"ProxyPort": "...",
**"BingSubscriptionKey": "65d5......"** <- Here
}
Let's have a look at the three steps to the implementation:
Step 1. Get an authentication token from the Azure Authentication Service using your subscription key.
# AzureAutenticationService
using (var client = _proxyClientService.CreateHttpClient())
{
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", subscriptionKey);
var uriBuilder = new UriBuilder(fetchUri);
uriBuilder.Path += "/issueToken";
var result = await client.PostAsync(uriBuilder.Uri.AbsoluteUri, null);
return await result.Content.ReadAsStringAsync();
}
Step 2. Parse your file/base64 string into a memory stream and buffer it into a HttpWebRequest object.
# BingSpeechService
var bytes = Convert.FromBase64String(audioBase64);
using (var memoryStream = new MemoryStream(bytes))
{
// Open a request stream and write 1024 byte chunks in the stream one at a time.
using (var requestStream = request.GetRequestStream())
{
// Read 1024 raw bytes from the input audio file.
var buffer = new byte[checked((uint) Math.Min(1024, (int) memoryStream.Length))];
int bytesRead;
while ((bytesRead = memoryStream.Read(buffer, 0, buffer.Length)) != 0)
{
requestStream.Write(buffer, 0, bytesRead);
}
// Flush
requestStream.Flush();
}
Step 3. Call the response and process the JSON response.
# BingSpeechService
using (var response = request.GetResponse())
{
var statusCode = ((HttpWebResponse) response).StatusCode.ToString();
int.TryParse(statusCode, out var statusCodeInt);
string responseString;
using (var sr = new StreamReader(response.GetResponseStream() ?? throw new InvalidOperationException()))
{
responseString = sr.ReadToEnd();
}
return new SpeechRecognitionResult()
{
StatusCode = statusCodeInt,
JSONResult = responseString,
ExternalServiceTimeInMilliseconds = sw.ElapsedMilliseconds
};
}
This process can be seen within two services in the provided code, BingSpeechService and AzureAuthenticationService. The settings are passed in through the URL, the main one being language.
Results
I've tested the process using a few sound files and it seems to be pretty accurate once configured correctly. It roughly takes a couple of seconds to process, so it's fairly snappy too! The response is returned in the form below:
{
OK
{
"RecognitionStatus": "Success",
"Offset": 22500000,
"Duration": 21000000,
"NBest": [{
"Confidence": 0.941552162,
"Lexical": "find a funny movie to watch",
"ITN": "find a funny movie to watch",
"MaskedITN": "find a funny movie to watch",
"Display": "Find a funny movie to watch."
}
}
Overall I've found the service simple to use and effective! Unfortunately, you can only process sound clips up to 10 seconds long with the API alone, any longer and you'll have to use the client library. I'll compare the features of the service with the other services later in this post.
IBM Watson
The second service, IBMs Watson is also a pretty easy service to configure and use, it can be done in one call!
Pros
- It's fast.
- Easy to implement.
Cons
- Does not support as many languages as Bing Speech.
Implementation
Implementing Watson is again pretty straightforward, you can sign up for a free account here. The process is exactly the same as Bing Speech except without the Authentication token, the username and password are passed straight in. If you're using the provided code, you will need to add your Watson subscription details into the appsettings.json file.
public SpeechRecognitionResult ParseSpeectToText(string[] args)
{
var base64String = args[0];
using (var client = _httpProxyClientService.CreateHttpClient())
{
client.DefaultRequestHeaders.Accept.Clear();
client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue(
"Basic", Convert.ToBase64String(
Encoding.ASCII.GetBytes(_username + ":" + _password)));
var bytes = Convert.FromBase64String(base64String);
var content = new StreamContent(new MemoryStream(bytes));
content.Headers.ContentType = new MediaTypeHeaderValue("audio/wav");
Stopwatch sw = new Stopwatch();
sw.Start();
var response = client.PostAsync("https://stream.watsonplatform.net/speech-to-text/api/v1/recognize?continuous=true&_model=" + _model,
content).Result;
if (!response.IsSuccessStatusCode) return null;
var res = response.Content.ReadAsStringAsync().Result;
sw.Stop();
return new SpeechRecognitionResult()
{
JSONResult = res,
StatusCode = 200,
ExternalServiceTimeInMilliseconds = sw.ElapsedMilliseconds
};
}
}
Again the URL takes parameters for the settings, so these can be configured as you see fit to serve your purpose. Model is the main parameter that handles language and the quality of the sound file.
Results
There can be multiple responses from the API but will take on this form:
{
"results":[
{"alternatives":[{"confidence":0.764,
"transcript":"testing one two three"}],
"final":true
}],
"result_index":0,
"warnings":["Unknown arguments:continuous."
]
}
Overall IBMs Watson is a pretty solid choice. It does not have Bings sound clip time limit which is a plus but does not have as many supported languages which could sway your decision on which one to use. In general testing, it does fall slightly short on accuracy compared to Bing Speech. Next up, AWS Transcribe.
AWS Transcribe
AWS transcribe put simply is not the easiest of services to use, it feels like it has been designed to work with Landa expressions meaning you get tied into the AWS infrastructure. However, it does have one major fundamental difference from the other services, it processes punctuation! It does so at a significant cost to its speed though!
Pros
- Calculates punctuation.
- Sound files can be preserved in S3 storage.
- Transcribed files are stored for x amount of time so they don't need to be reprocessed.
Cons
- Slow.
- Tricky to set up.
- Very limited language choice.
Implementation
So why is AWS Transcribe a bit tricky to set up? You need to set up S3 storage to store your files, as well as user configuration and the transcribe service itself. If you're handling files already that's fine but if you're using base64 strings from a front end client there's a lot of conversions going on. Firstly sign up for a free account here. You're also going to need the AWS Visual Studio Toolkit. Before opening Visual Studio, you should run through the IAM best practices to set up a non-root user. The next time you open Visual Studio you'll be prompted for your username and keys, if you've not got them already you can grab them through the IAM user panel shown below.
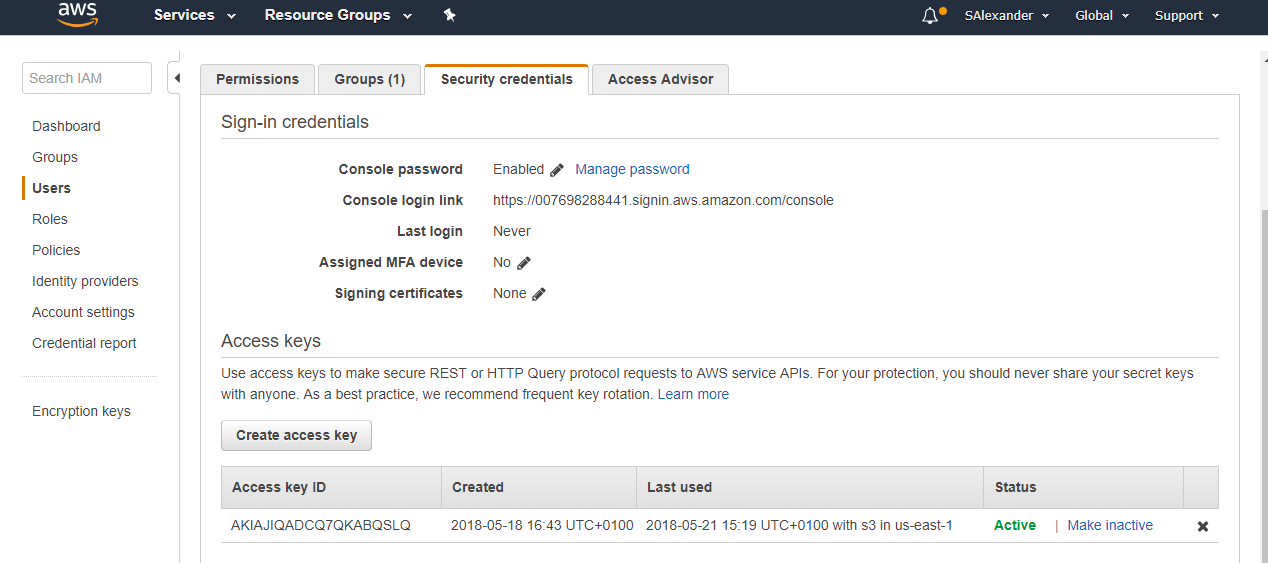
By providing our details to Visual studio, not only will we now have access to the AWS Explorer. There is also an AWS configuration file configured into our Visual Studio environment. Now that's setup, here are the steps to run the speech to text conversion.
Step 1. Upload a file / base64 string into an S3 bucket. Not just any bucket, one that's been created in us-east-1. You can do this through the AWS explorer panel or through the AWS browser console. Once it exists, the following is the code that will convert your base64 string into a WAV file and upload it to the bucket.
#AmazonUploaderService
byte[] bytes = Convert.FromBase64String(base64);
var filename = "S2C" + DateTime.UtcNow.ToString("ddMMyyyyhhmmss") + ".wav";
var request = new PutObjectRequest
{
BucketName = _bucketName,
CannedACL = S3CannedACL.PublicRead,
Key = filename
};
using (var ms = new MemoryStream(bytes))
{
request.InputStream = ms;
await _amazonS3Client.PutObjectAsync(request);
return new S3UploadResponse()
{
BucketName = _bucketName,
FileRoute = filename,
BucketRegion = _amazonS3Client.Config.RegionEndpoint.SystemName
};
}
Step 2. Create and trigger a transcribe job. Note this is only the triggering, this process won't return the response.
#AWSService
var transciptionJobName = "Transcribe_" + uploadDetails.FileRoute;
var request = new StartTranscriptionJobRequest()
{
Media = new Media()
{
MediaFileUri = "https://s3." + uploadDetails.BucketRegion + ".amazonaws.com/" + uploadDetails.BucketName + "/" + uploadDetails.FileRoute
},
LanguageCode = new LanguageCode(LanguageCode.EnUS),
MediaFormat = new MediaFormat("Wav"),
TranscriptionJobName = transciptionJobName
};
Step 3. Poll the AWS service for the job status until complete.
#AWSService
while (!jobComplete)
{
jobRes = await _amazonTranscribeService.GetTranscriptionJobAsync(new GetTranscriptionJobRequest()
{
TranscriptionJobName = transciptionJobName
});
if (jobRes != null && jobRes.TranscriptionJob.TranscriptionJobStatus !=
TranscriptionJobStatus.COMPLETED)
{
System.Threading.Thread.Sleep(5000);
}
else
{
jobComplete = true;
}
}
Step 4. Create a HttpClientRequest to the new transcribe job resource (the URL containing the result is returned in the job status request, it's not contained directly).
#AWSService
using (var client = _httpProxyClientService.CreateHttpClient())
{
client.DefaultRequestHeaders.Accept.Clear();
client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
var response = client.GetAsync(jobRes.TranscriptionJob.Transcript.TranscriptFileUri).Result;
if (!response.IsSuccessStatusCode) return null;
jsonRes = response.Content.ReadAsStringAsync().Result;
}
Step 5. Delete the uploaded file from the S3 bucket (otherwise you will be billed for storage at some point).
# AmazonUploaderService
var res = await _amazonS3Client.DeleteObjectAsync(_bucketName, filename);
Results
The polling process alone puts me off this process, let alone how slow it is. Yet it does not mean that the Transcribe service does not have a place. For non-real-time applications where punctuation is a critical factor then it's ideal! The response is also broken down word by word by default with timestamps which is a nice feature:
"jobName": "Transcribe_S2C21052018021806.wav",
"accountId": "007698288441",
"results": {
"transcripts": [{
"transcript": "Because in one two, three."
}],
"items": [{
"start_time": "0.250",
"end_time": "0.470",
"alternatives": [{
"confidence": "0.9666",
"content": "Because"
}],
"type": "pronunciation"
},
{
"start_time": "0.470",
"end_time": "0.570",
"alternatives": [{
"confidence": "0.9993",
"content": "in"
}],
"type": "pronunciation"
},...
]
},
"status": "COMPLETED"
In conclusion to AWS, I'd not consider it for any real-time applications but may find some use in offline tasks, especially since it shows itself to be the most accurate of the three when dealing with large files. It should also tie in nicely with other AWS services which is worth bearing in mind.
Key Comparison
The following table has been created from the data contained within the documentation of the three services:
| Bing Speech | IMB Watson | AWS Translate | |
|---|---|---|---|
| Languages | Interactive / Dictate mode 29 • Arabic (Egypt) (ar-EG) Conversation Mode (10) • Arabic (ar-EG) | Language Model customization
• French Acoustic Model Customization (Beta) • Brazilian Portuguese | • English • Spanish *Processes punctuation! |
| Input Types | • ssml-16khz-16bit-mono-tts • raw-16khz-16bit-mono-pcm • audio-16khz-16kbps-mono-siren • riff-16khz-16kbps-mono-siren • riff-16khz-16bit-mono-pcm • audio-16khz-128kbitrate-mono-mp3 • audio-16khz-64kbitrate-mono-mp3 • audio-16khz-32kbitrate-mono-mp3 | • audio/basic • audio/flac • audio/l16 • audio/mp3 • audio/mpeg • audio/mulaw • audio/ogg • audio/ogg;codecs=opus • audio/ogg;codecs=vorbis • audio/wav • audio/webm • audio/webm;codecs=opus • audio/webm;codecs=vorbis |
16 & 8 kHz audio streams
• WAV |
| Websocket support | Yes | Yes | No |
| Implementation | Easy | Easy | Complex |
| Processing Time | Seconds | Seconds | 1-3 Minutes |
| Pricing | • 5,000 free transactions per month
• £2.982 per 1,000 transactions | • 100 minutes free per month then… • 1-250,000 $0.02 per min. • 250,000 – 500,000 $0.015 per min. • 500,000-1,000,000 $ 0.0.125 per min. • 1,000,000 $0.01 per min |
• 60 Minutes free per month for 12 months
• $0.0004 per second |
Comparison results
The results can vary greatly, however, when using short phrases Bing Speech comes out on top for accuracy and speed. On the other hand, AWS Transcribes accuracy seems to be the best for long sound files, although slow. An example result can be seen in the image below using the following extract from Frankenstein "It was on a dreary night of November that I beheld the accomplishment of my toils. With an anxiety that almost amounted to agony".
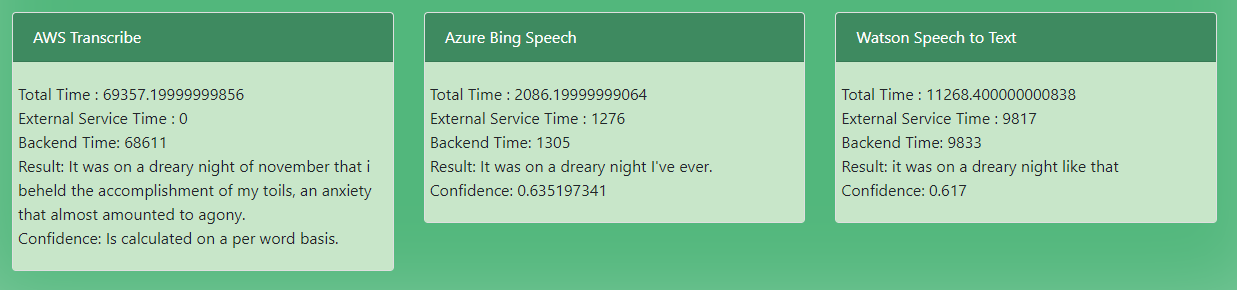
Conclusion
This has been a nice stepping stone into Speech to Text services, although not perfect they can be considered usable. I feel this project is not complete yet as Azure and AWS have updated services in beta, so the exploration process is likely to continue in the near future. I hope this has been useful so far.
Comments